How to Analyse post-IR IRSL Measurements?
by Sebastian Kreutzer (February 20, 2020)
Creative Commons
Attribution-NonCommercial-NoDerivatives 4.0
International License
Using the function analyse_SAR.CWOSL() and Analyse_SAR.OSLdata() from the R package ‘Luminescence’ allows to analyse standard OSL (quartz) measurements based on the SAR protocol (Murray and Wintle 2000).
The function analyse_SAR.CWOSL() can also be used for analysing measurements based on the post-IR IRSL protocol (pIRIR, Thomsen et al. (2008)), since the measurement
protocol based on the SAR structure (see the following table)
comprising a set of curves with a \(L_{x}\) and \(T_{x}\) signal pattern.
| Step | Example | Signal |
|---|---|---|
| Irradiation | beta-irr. | - |
| Heating | preheat/TL | - |
| Stimulation | OSL | \(L_x\) |
| Irradiation | beta-irr. | - |
| Heating | cutheat/TL | - |
| Stimulation | OSL | \(T_x\) |
To lower the entry level and make the analysis of post-IR IRSL data more straightforward, some time ago, the function analyse_pIRIRSequence() was developed. This function is basically a wrapper around the two functions analyse_SAR.CWOSL() and plot_GrowthCurve().
This vignette provides a short tutorial exemplifying the analysis of post-IR IRSL data in R. To avoid misunderstandings, please keep in mind that the post-IR IRSL protocol is a simple extension of the SAR structure by introducing further stimulations steps only:
| Step | Example | Signal |
|---|---|---|
| Irradiation | beta-irr. | - |
| Heating | preheat/TL | - |
| Stimulation | IR\(_{50}\) | \(L_{x_{_1}}\) |
| Stimulation | pIRIR\(_{225}\) | \(L_{x_{_2}}\) |
| Irradiation | beta-irr. | - |
| Heating | preheat/TL | - |
| Stimulation | IR\(_{50}\) | \(T_{x_{_1}}\) |
| Stimulation | pIRIR\(_{225}\) | \(T_{x_{_2}}\) |
While the number of IRSL stimulation steps is not limited in general (cf. Fu, Li, and Li (2012)), the number of steps
used for recording the signal of interest and the test dose signal must be equal.
Example, if the sequence has two stimulation steps for the signal (\(L_{x_{_1}}\), \(L_{x_{_2}}\))
(as in the table given above), it also needs two stimulations steps for measuring the test dose.
Further steps, e.g., hot bleach steps at the end of the cycle, are allowed, but do not belong
to the SAR structure and should be removed prior any analysis using the function analyse_pIRIRSequence().
Note: The terminal and graphical output show below is partly truncated to shorten the length of this vignette, however, calling the functions in R will show the full output.
Running example
In our example, the measurement was carried out on a Freiberg Instruments lexsyg luminescence reader. Measurement data are stored in XML-based file format called XSYG. Two pIRIR signals were measured: A IR\(_{50}\) and a pIRIR\(_{225}\) signal. The preheat steps were carried out as TL.
Data import
To start with, the package ‘Luminescence’ itself has to be loaded. In a next step,
measurement data are imported using the function read_XSYG2R(). If your input format is a BIN/BINX-file,
replace the function read_XSYG2R() by read_BIN2R().
library(Luminescence)
temp <- read_XSYG2R(XSYG_file, fastForward = TRUE, txtProgressBar = FALSE)To se the dataset in the R terminal, just call the object temp
temp## [[1]]
##
## [RLum.Analysis-class]
## originator: read_XSYG2R()
## protocol: pIRIR225
## additional info elements: 0
## number of records: 229
## .. : RLum.Data.Curve : 229
## .. .. : #1 TL (UVVIS) <> #2 TL (NA) <> #3 TL (NA)
## .. .. : #4 IRSL (UVVIS) <> #5 IRSL (NA) <> #6 IRSL (NA) <> #7 IRSL (NA) <> #8 IRSL (NA)
## .. .. : #9 IRSL (UVVIS) <> #10 IRSL (NA) <> #11 IRSL (NA) <> #12 IRSL (NA) <> #13 IRSL (NA)
## .. .. : #14 irradiation (NA)
## .. .. : #15 TL (UVVIS) <> #16 TL (NA) <> #17 TL (NA)
## .. .. : #18 IRSL (UVVIS) <> #19 IRSL (NA) <> #20 IRSL (NA) <> #21 IRSL (NA) <> #22 IRSL (NA)
## .. .. : #23 IRSL (UVVIS) <> #24 IRSL (NA) <> #25 IRSL (NA) <> #26 IRSL (NA) <> #27 IRSL (NA)
## ... <remaining records truncated manually>The output shows an RLum.Analysis object, which contains all recorded curves (RLum.Data.Curve objects)
from one aliquot (e.g., cup/disc). In total, the dataset contains the curves of 7 aliquots. All records are numbered, here from #1 to #208 (shown only until #29) and named by their corresponding record type (TL, IRSL). So far available, within round brackets, information on the detector are given (UVVIS and NA). This reveals that the object contains curves which are not wanted for the analysis.
Curves which belong to a specific measurement step (e.g., IRSL stimulation) are connected with the <> symbol.
However, curves with (NA) are curves recorded by technical components (e.g., temperature sensor) other than the photomultiplier tube and not wanted, even they belong to the dataset. In our case, unfortunately, the information (UVVIS) is rather uninformative, but a usual case, since it depends on the measurement device whether information on the detector are available or not. This example emphasises that prior knowledge of the data structure and the used technical components are indispensable.
Select wanted curves
To select only wanted curves wanted for the analysis the function get_RLum() can be used:
temp_sel <- get_RLum(temp, recordType = "UVVIS", drop = FALSE)temp_sel## [[1]]
##
## [RLum.Analysis-class]
## originator: read_XSYG2R()
## protocol: pIRIR225
## additional info elements: 0
## number of records: 49
## .. : RLum.Data.Curve : 49
## .. .. : #1 TL (UVVIS) | #2 IRSL (UVVIS) | #3 IRSL (UVVIS) | #4 TL (UVVIS) | #5 IRSL (UVVIS) | #6 IRSL (UVVIS) | #7 IRSL (UVVIS)
## .. .. : #8 TL (UVVIS) | #9 IRSL (UVVIS) | #10 IRSL (UVVIS) | #11 TL (UVVIS) | #12 IRSL (UVVIS) | #13 IRSL (UVVIS) | #14 IRSL (UVVIS)
## ... <remaining records truncated manually>The function get_RLum() is very powerful and supports sophisticated subsetting of a RLum.Analysis objects.
Further useful arguments are curveType and record.id. The latter one allows a subsetting by record
id (e.g., record.id = 2 to select #2) and supports also negative subsetting (e.g., to remove only #2, type
record.id = -2). To understand the meaning of the argument drop = FALSE, please call the function get_RLum()
another time with drop = TRUE and see the difference in the R terminal.
For all supported arguments see the manual of the function by typing ?get_RLum in the R terminal.
In our example, however, the dataset does not yet follow the SAR structure. The sequence comprises a
hotbleach at the end of each cycles (record #7 in the terminal output example above). This curves are not
wanted a have to be removed. This can be done using again the function get_RLum() with the argument
record.id. Please note that by executing the following example the object temp_sel will be replaced.
temp_sel <- get_RLum(temp_sel, record.id = -seq(7,length(temp_sel[[1]]), by = 7), drop = FALSE)temp_sel## [[1]]
##
## [RLum.Analysis-class]
## originator: read_XSYG2R()
## protocol: pIRIR225
## additional info elements: 0
## number of records: 42
## .. : RLum.Data.Curve : 42
## .. .. : #1 TL (UVVIS) | #2 IRSL (UVVIS) | #3 IRSL (UVVIS) | #4 TL (UVVIS) | #5 IRSL (UVVIS) | #6 IRSL (UVVIS) | #7 TL (UVVIS)
## .. .. : #8 IRSL (UVVIS) | #9 IRSL (UVVIS) | #10 TL (UVVIS) | #11 IRSL (UVVIS) | #12 IRSL (UVVIS) | #13 TL (UVVIS) | #14 IRSL (UVVIS)
## ... <remaining records truncated manually>Using a negative subsetting, all hotbleach curves have been removed using the call
-seq(7,length(temp_sel[[1]]), by = 7). Important is to understand that the function length()
was called for the first list element of temp_sel, which contains the recorded curves for the first
aliquot only. To see the differences type:
length(temp_sel)## [1] 7length(temp_sel[[1]])## [1] 42In other words, our measurement record has data from 7 aliquots and each aliquot consits of (at least) 42 records. We here further assume that the number of records is similar for each aliquot.
Analyse sequence
Now the object temp_sel only comprises TL and IRSL curves, and this data can be directly
passed to the function analyse_pIRIRSequence():
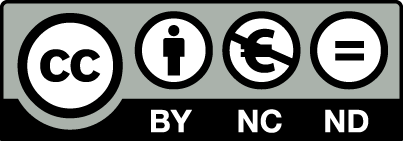
results <- analyse_pIRIRSequence(
object = temp_sel[[1]],
signal.integral.min = 1,
signal.integral.max = 10,
background.integral.min = 800,
background.integral.max = 999,
dose.points = c(0, 340, 680, 1020, 1360, 0, 340),
verbose = FALSE)
The function expects the setting of some arguments, for details and meaning, please see ?analyse_pIRIRSequence.
If the imported measurement data do not carry information on the dose.points, as it is the case in our example, these
values have to be provided manually. Please note that the information needed for dose.points is something
which was defined while writing the measurement sequence (your irradiation times).
The function output is a comprehensive plot scheme and a so-called RLum.Results object, which contains
all relevant calculations from the analysis.
results##
## [RLum.Results-class]
## originator: analyse_pIRIRSequence()
## data: 4
## .. $data : data.frame
## .. $LnLxTnTx.table : data.frame
## .. $rejection.criteria : data.frame
## .. $Formula : list
## additional info elements: 14The \(D_{e}\) values (here in seconds) can be seen by calling the $data element from the object results,
which is a data.frame (and here limited to three columns):
results$data[,c("De", "De.Error", "RC.Status", "Signal")]## De De.Error RC.Status Signal
## 1 803.5434 40.24659 OK IR50
## 2 1099.8584 27.25066 OK pIRIR225
## 3 632.8027 27.26445 OK IR50
## 4 873.7713 30.90966 OK pIRIR225
## 5 1166.2585 26.66646 OK IR50
## 6 1058.8393 21.20152 OK pIRIR225
## 7 741.3041 31.01709 FAILED IR50
## 8 1049.1700 29.43378 OK pIRIR225
## 9 873.9625 68.01513 OK IR50
## 10 1236.3436 58.70168 OK pIRIR225
## 11 827.6762 37.62984 OK IR50
## 12 1095.2448 29.54729 OK pIRIR225
## 13 714.1201 26.92116 OK IR50
## 14 807.3030 18.75932 OK pIRIR225The column RC.Status informs you about a failed rejection criterium, which one is not revealed,
but the column provides a possibilty for further subsetting. For a quick data processing this is,
together with the plot output, usually enough information. However, to see all rejection criteria
type results$rejection.criteria. To see all information type results$data without further information.
If you want to combine the two tables for a more virtous data processing, you can merge both tables by calling:
df <- merge(results$data, results$rejection.criteria, by = "UID")
head(df)## UID De De.Error D01 D01.ERROR D02
## 1 2021-08-23-06:59.0.0329082782845944 1095.245 29.54729 868.9854 40.66528 NA
## 2 2021-08-23-06:59.0.0329082782845944 1095.245 29.54729 868.9854 40.66528 NA
## 3 2021-08-23-06:59.0.0329082782845944 1095.245 29.54729 868.9854 40.66528 NA
## 4 2021-08-23-06:59.0.0329082782845944 1095.245 29.54729 868.9854 40.66528 NA
## 5 2021-08-23-06:59.0.0329082782845944 1095.245 29.54729 868.9854 40.66528 NA
## 6 2021-08-23-06:59.0.0843403427861631 1099.858 27.25066 1256.2677 76.38328 NA
## D02.ERROR Dc De.MC Fit HPDI68_L HPDI68_U HPDI95_L HPDI95_U RC.Status
## 1 NA NA 1086.710 EXP 1052.935 1112.121 1031.062 1153.294 OK
## 2 NA NA 1086.710 EXP 1052.935 1112.121 1031.062 1153.294 OK
## 3 NA NA 1086.710 EXP 1052.935 1112.121 1031.062 1153.294 OK
## 4 NA NA 1086.710 EXP 1052.935 1112.121 1031.062 1153.294 OK
## 5 NA NA 1086.710 EXP 1052.935 1112.121 1031.062 1153.294 OK
## 6 NA NA 1101.196 EXP 1071.219 1128.511 1044.722 1155.008 OK
## signal.range background.range signal.range.Tx background.range.Tx Signal.x
## 1 1 : 10 800 : 999 NA : NA NA : NA pIRIR225
## 2 1 : 10 800 : 999 NA : NA NA : NA pIRIR225
## 3 1 : 10 800 : 999 NA : NA NA : NA pIRIR225
## 4 1 : 10 800 : 999 NA : NA NA : NA pIRIR225
## 5 1 : 10 800 : 999 NA : NA NA : NA pIRIR225
## 6 1 : 10 800 : 999 NA : NA NA : NA pIRIR225
## Criteria Value Threshold Status Signal.y
## 1 Recycling ratio (R5/R1) 1.025500e+00 0.1 OK pIRIR225
## 2 Recuperation rate 1 5.300000e-03 0.1 OK pIRIR225
## 3 Testdose error 1.102687e-02 0.1 OK pIRIR225
## 4 Palaeodose error 2.698000e-02 0.1 OK pIRIR225
## 5 De > max. dose point 1.095245e+03 1360.0 OK pIRIR225
## 6 Recycling ratio (R5/R1) 1.055200e+00 0.1 OK pIRIR225The result may appear confusing in a first instance, since, e.g. the column De appears to contain duplicated
entries. But still, each row is unique and in sum contains unique information.
Plot results
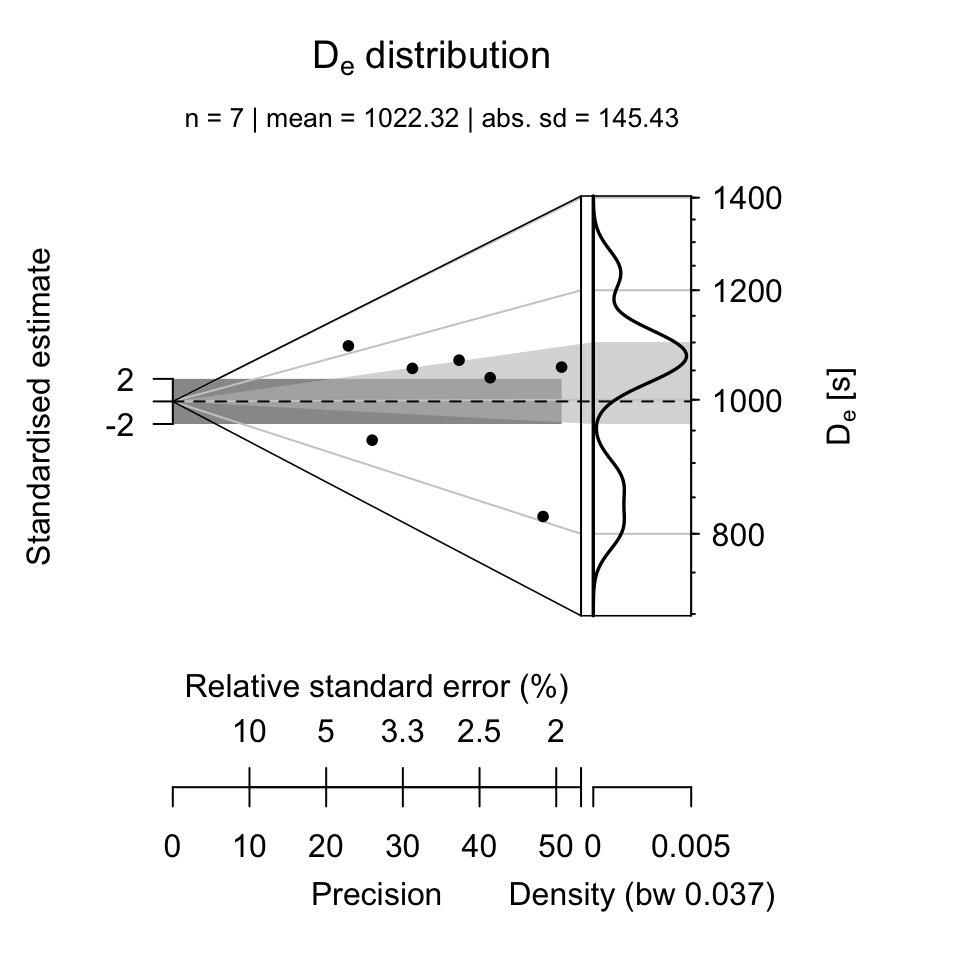
To plot the pIRIR225 \(D_{e}\) values the following call can be used:
plot_KDE(
data = subset(results$data, Signal == "pIRIR225")[, c("De", "De.Error")],
xlab = expression(paste(D[e], " [s]")),
summary = c("n", "mean", "sd.abs"))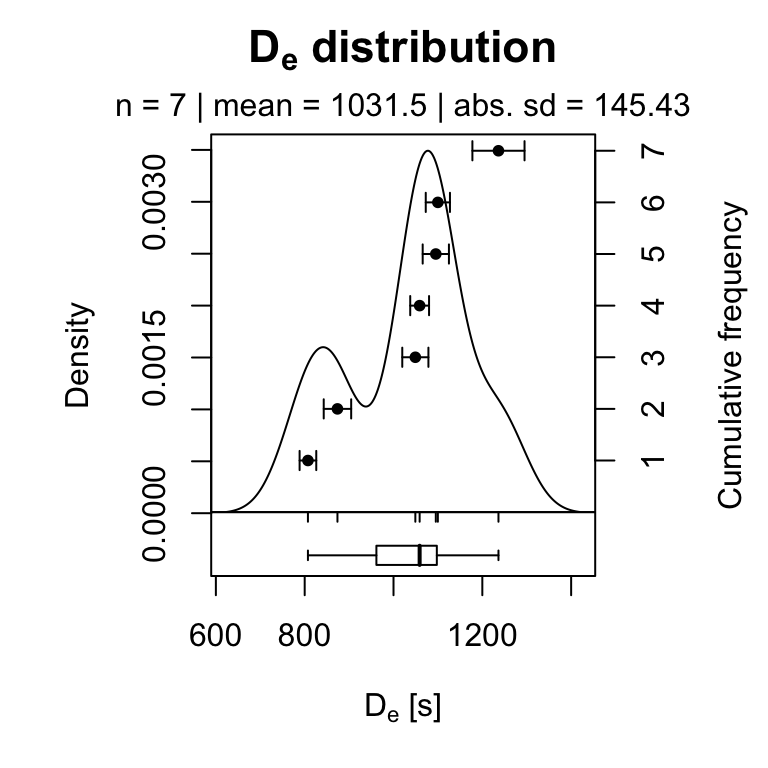
Compacted call
The above-listed steps can also be shortened to a concise R call using the |> pipe operator
introduced with R 4.1. To have a difference to the previous example, the final
plot is an Abanico plot (Dietze et al. 2016).
Please note that for this last example the arguments plot and verbose have been set to
FALSE for most of the functions.
results <- read_XSYG2R(XSYG_file, fastForward = TRUE, verbose = FALSE) |>
get_RLum(recordType = "UVVIS", drop = FALSE) |>
get_RLum(record.id = -seq(7,49, by = 7), drop = FALSE) |>
analyse_pIRIRSequence(
signal.integral.min = 1,
signal.integral.max = 10,
background.integral.min = 800,
background.integral.max = 999,
dose.points = c(0, 340, 680, 1020, 1360, 0, 340),
verbose = FALSE,
plot = FALSE) |>
get_RLum() |>
subset(subset = Signal == "pIRIR225") |>
plot_AbanicoPlot(
zlab = expression(paste(D[e], " [s]")),
summary = c("n", "mean", "sd.abs"))